Andrew Ng - deeplearning.ai - 第二课第一周学习笔记¶
内容概要:
- 训练集、验证集、测试集(train、dev、test sets)的意义以及如何划分
- 偏差和方差(bias and variance)的区别,如何处理高偏差、高方差以及两者共存的问题
- 使用正则化方法降低过拟合风险,如:L2正则化、dropout等
- Normalizing inputs - 加快神经网络训练速度的方法
- 参数初始化方法
1 - 数据集划分(train、dev、test)¶
数据集的划分是机器学习的一项重要内容,不适合的划分方法会导致训练得到的模型完全不可用;一种合适的数据集划分方法是得到一个高性能、高可用模型的大前提。
通常,数据集会被划分成三个部分,即训练集(train set)、交叉验证集(dev set)、测试集(test set),如下图:

训练集用于模型的训练,交叉验证集用于检验模型训练的效果,测试集用于确定模型的最终性能、判断模型是否可用。交叉验证集和测试集的作用比较容易搞混淆,他们的本质区别是:模型可以在交叉验证集上跑很多次,但是只能在测试集上面跑一次,并且,在多数情况下,训练模型的时候可以不需要测试集。(习惯上,当数据集被划分成两部分时,人们分别称他们为训练集和测试集,但是这里的测试集,其实起到的是交叉验证集的作用!)
如果数据集比较小,可以按照6:2:2(train:dev:test)的比例进行划分;当数据集很大时,就没有必要按照这个比例来划分了,应当在满足验证、测试需求的情况下,尽可能多的把数据用于训练,比如,对1000000行的数据集,分别抽取10000行用作验证和测试就够了。另外,在多数情况下,没有test set也是可以的,即仅仅把数据集划分成train set 和 dev set;这时,小数据集可以按照7:3(train:dev)进行划分。
数据集划分中另外一个值得关注的问题是 训练集和测试集必须来自同一数据分布,简单的理解是训练集和测试集的数据应当来自相同的数据源。
关于train、dev、test的更通俗解释,请点击查看【不能更简单通俗的机器学习基础名词解释】
2 - 偏差(Bias) & 方差 (Variance)¶
算法在不同训练集上学习得到的模型往往并不相同,即便这些训练集来自同一个分布。因此,有效的评估习得模型的泛化性能显得十分重要。模型的泛化性能与偏差(Bias)和方差(Variance)密切相关,事实上,泛化误差可以认为了偏差、方差、噪声(误差下界,通常用一个专家团队的误差极限代替)之和。
2.1 - 是什么?¶
偏差是算法的拟合能力的度量,它反映了模型预测结果与真实结果的偏离程度; 方差刻画了训练集的轻微变动对算法学习性能的影响。
2.2 - 如何识别?¶
提高模型泛化性能,首先应当识别模型当前是偏差过大还是方差过大。在课程视频中,ng用下图给了我们一个感性认识,即:偏差过大体现在模型欠拟合;方差过大则体现在模型过拟合。
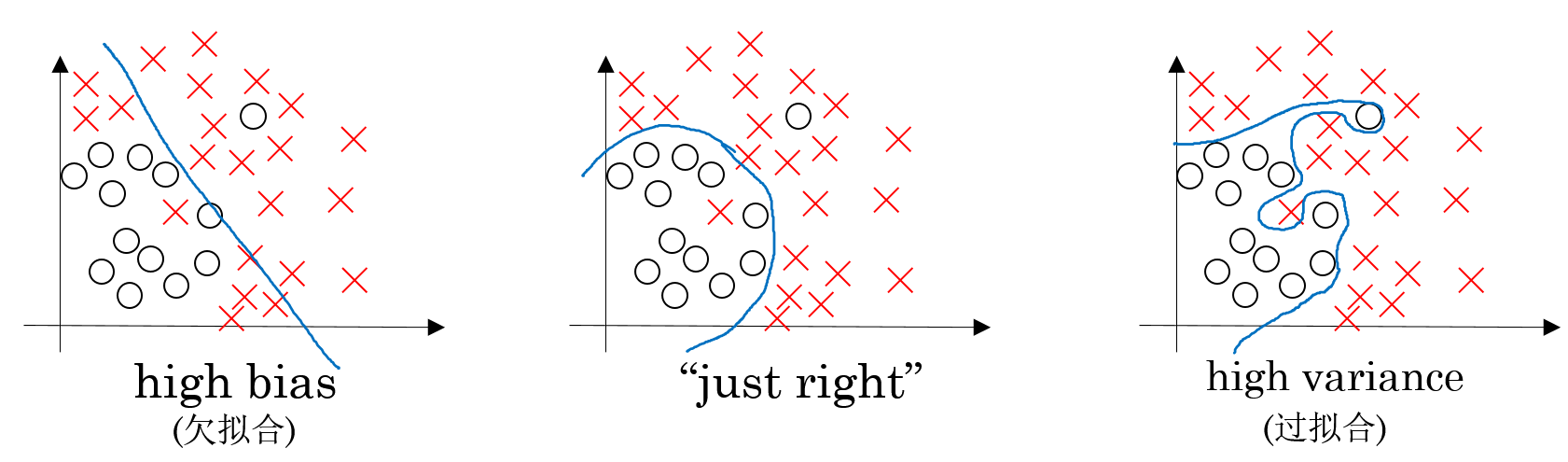
为了帮助我们进一步提高识别能力,ng以cat classification(噪声约等于0%)为例,列出下表:
| 训练误差 | 测试误差 | 对应分析 |
|---|---|---|
| 1% | 11% | 方差过大 |
| 15% | 16% | 偏差过大 |
| 15% | 30% | 方差和偏差都过大 |
| 0.5% | 1% | 正合适 |
从上表可以看出,一个合适的习得模型,训练误差和测试误差都与噪声接近;训练误差偏离噪声过大,则模型的偏差过大;测试误差明显大于训练误差,则模型的方差偏大。
2.3 - 怎么解决?¶
针对偏差过大和方差过大的处理方法,ng总结成以下流程图:
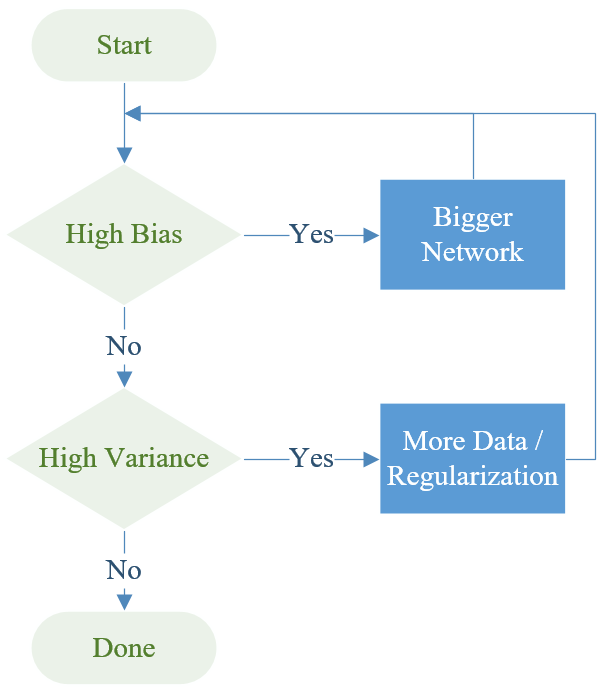
从上图可以看出:偏差过大,可以使用更大的网络来提高拟合性能;方差过大,则需要更多的数据进行训练,或者使用正则化方法降低模型过拟合风险。
偏差和方差有冲突,即模型拟合的不好时,偏差过大,数据扰动的影响很小,方差就小;当模型拟合性能增强之后,偏差小了,但是,此时数据扰动的影响变大,方差就大了。因此,在处理方差和偏差的时候,往往要进行权衡,即 Bias-Variance Trade Off.
Note:关于偏差和方差的更深入讲解,请查阅《机器学习(周志华)》 2.5 偏差与方差!
3 - 正则化(Regularization)¶
对于深度学习算法而言,过拟合(overfitting)是一个严重的问题,特别是数据集不大的时候。过拟合的意思是,模型在学习到训练集上的普遍特征的同时,把训练集上的一些非普遍特征也学到了,这样的直接后果是习得模型的泛化性能特别低,以致无法应用到新的数据样本上。过拟合的模型往往方差偏大。
降低算法过拟合风险的Regularization(正则化)方法有不少,比如:L2 regularization、Dropout、data augmention(数据增强,即扩大数据集)、early stopping(早停,即依据训练误差曲线和测试误差曲线来决定什么时候停止训练)等。
在实践中,常用的正则化方法有两个:L2 regularization 和 Dropout,这主要是因为这两种方法操作起来相对简单,而且效果也很不错。
使用Regularization方法可以降低模型在训练集上的表现,训练误差变大,避免习得模型过拟合;从而提高模型在测试集上的表现。
3.1 - L2 regularization¶
L2 regularization是避免模型过拟合的最常用方法之一,它仅仅是在cost function 后面加上了一项L2 regularization cost,将cost function 由:
$$J = -\frac{1}{m} \sum\limits_{i = 1}^{m} \large{(}\small y^{(i)}\log\left(a^{[L](i)}\right) + (1-y^{(i)})\log\left(1- a^{[L](i)}\right) \large{)} \tag{1}$$转变成: $$J_{regularized} = \small \underbrace{-\frac{1}{m} \sum\limits_{i = 1}^{m} \large{(}\small y^{(i)}\log\left(a^{[L](i)}\right) + (1-y^{(i)})\log\left(1- a^{[L](i)}\right) \large{)} }_\text{cross-entropy cost} + \underbrace{\frac{1}{m} \frac{\lambda}{2} \sum\limits_l\sum\limits_k\sum\limits_j W_{k,j}^{[l]2} }_\text{L2 regularization cost} \tag{2}$$
在 L2 regularization cost 项中,$\lambda$ 是一个超参,通常设置在0.6-0.8之间。L2正则化能够使模型的决策边界(decision boundary)更加平滑,但是,$\lambda$设置的太大,有可能过于平滑(oversmooth),导致模型偏差变大(即模型欠拟合)。施加L2正则化之后,模型中的权重系数倾向于变得更小。
需要注意的是,cost function增加了L2正则项之后,对应的向后传播计算过程也要相应的更新计算公式。由于L2 regularization cost 仅考虑了 $W$,因此,仅仅需要改变各层的$dW$计算公式,即都加上 $\frac{\lambda}{m} W$
What is L2-regularization actually doing?
L2-regularization relies on the assumption that a model with small weights is simpler than a model with large weights. Thus, by penalizing the square values of the weights in the cost function you drive all the weights to smaller values. It becomes too costly for the cost to have large weights! This leads to a smoother model in which the output changes more slowly as the input changes.
3.2 - Dropout¶
dropout 是一个广泛用于深度学习算法的正则化方法,它通过在每次迭代(iteration)中根据keepprob参数随机关闭部分神经元来降低过拟合风险。**所谓关闭神经元,其实就是将该神经元的输出 $a{i}^{[l]}$ 设置为0**。
在当前迭代过程中,被关闭的神经元在向前传播过程和向后传播过程中都不会起作用。所以,使用Dropout方法关闭某些神经元(neurous)之后,事实上已经改变了模型。Dropout背后的核心思想是:在每一次迭代中,仅使用部分神经元来训练,得到一个不一样的模型,这意味着神经元之间的依赖性会降低,因为其他神经元随时都可能会被关闭。
Dropout能够有效降低过拟合风险的原因是:施加Dropout方法之后,神经元不能依赖任何一个特征,所有只能尽可能多的学习普遍特征。
4 - 标准化输入(Normalizing inputs)¶
4.1 - 为什么要标准化输入¶
标准化输入(normalizing inputs)是提高网络训练速度的一种有效方法,此外,它还能够避免训练过程中学习曲线的波动,降低错过最优值的风险。从下图可以看出,Normalizing inputs之后,cost function的空间分布变得更匀称,使用梯度下降法在该空间搜索最小值的过程就更快,而且几乎没有波动。

4.2 - 标准化输入的步骤¶
具体来说,将输入数据进行标准化包含两个步骤:1)去掉均值(subtract means);2)去掉多样性(normalize various)。效果见下图:

5 - 参数初始化¶
参数初始化是神经网络中一个相对重要的内容,一个合适的参数初始化方法不仅仅能够加快收敛的速度,而且可以提高获得一个更小的训练误差的概率。
神经网络中,需要初始化的参数有两个,分别是各层的 weights $W^{[l]}$ 矩阵 和 bias $b^{[l]}$ 向量;当 $W^{[l]}$ 随机初始化之后,$b^{[l]}$ 可以初始化为0。因此,事实上,我们只需要考虑 weights $W^{[l]}$ 的随机初始化方法。
针对 weights $W^{[l]}$,绝对不能初始化为0,如果 $W^{[L]}$的初始化值为0,那么神经网络的训练将无法进行;研究者已经证明,weights $W^{[l]}$ 的初始化值越随机、越小,效果越好。基于此,ng推荐的 $W^{[l]}$ 参数初始化方法是 "He Initialization",这个方法将 $W^{[l]}$ 初始化为sqrt(2./layers_dims[l-1])。
"Xavier initialization" 方法与 "He Initialization" 非常相似,它使用sqrt(1./layers_dims[l-1])将$W^{[l]}$ 初始化。TensorFlow中可以调用 tf.contrib.layers.xavier_initializer() 来实现该方法。
6 - 其他¶
6.1 - Vanishing/exploding gradients¶
随着网络层数的增加,梯度爆炸和梯度消失(Vanishing/exploding gradients)的问题逐步显现。详细介绍,请查看一下两篇Blog:
6.2 Gradient checking¶
Gradient checking implementation notes
- Don’t use in training – only to debug
- If algorithm fails grad check, look at components to try to identify bug.
- Remember regularization.
- Doesn’t work with dropout.
- Run at random initialization; perhaps again after some training.